Ragged Books

Konsulenthuset Thoughtworks udgiver halvårligt deres Tech Radar – en måde at gå lidt struktureret til værks, når man skal orientere sig i det teknologiske landskab. Det er en ret grundig omgang, der går i dybden med teknikker, tools, platforme og da jeg læste den sidste rapport i julen, var det selvfølgelig ikke overraskende, at AI fylder en del. For at sige det mildt.
Noget af hypen er dog ved at have sat sig, og der er begyndt at vise sig nogle mønstre i nyttige, praktiske anvendelser af AI, og en af dem er RAG-teknikken.
RAG står for Retrieval Augmented Generation og går ud på at fodre en generativ sprogmodel med nogle af dine egne data som kontekst til det, du spørger den om.
Det er i virkeligheden en uhyre simpel teknik, men dog med en del detaljer, der skal passe nogenlunde sammen for at det giver mening.
Fordi jeg lærer med fingrene, har jeg bygget et lille tool, Ragged Books, der kan hjælpe mig med at søge og sammenfatte i en lokal bogsamling.
Kontekst og constraints
Da ethvert meningsfuldt produkt er knyttet til et behov, der ikke i forvejen er løst, kommer her lidt mere kontekst og nogle af rammerne omkring mit lille eksperiment.
- Jeg har ca. 25 bøger om softwarearkitektur i pdf-form (ja, jeg har købt og betalt)
- Når jeg skal dykke ned i et emne, vil jeg gerne finde det bedste sted at starte i min bogsamling.
- Måske vil jeg have en LLM til at opsummere noget af det for mig.
- Jeg har ikke rettigheder til at dele bøgerne online, så det hele skal foregå i sikkerhed på min laptop.
- Det skal være nemt for mig at bruge.
- Det skal være sjovt for mig at bygge, og jeg skal blive klogere på nuancerne i de detaljer, der ALTID dukker op, når man stikker spaden i jorden.
- Jeg vil bruge .NET og Semantic Kernel frameworket. Normalt har jeg lavet mine hygge AI-eksperimenter med Python, men de opgaver jeg laver for kunder hos Eksponent, er fortrinsvist lavet på Microsofts teknologistak.
Tilgang
Det er en tretrinsraket:
- Import af bøger ind i en vektordatabase
- Semantisk søgning i bøgerne
- Få en LLM til at opsummere det fundne
Import af bøger
Hver bog skal splittes op i små bidder, der af en sprogmodel får hver deres "Embeddings", som er en slags koordinat for, hvor den kan placeres i det rum, som sprogmodellen udgør. I et normalt koordinatsystem har man (x,y), i et tredimensionelt rum har man (x,y,z), men her taler vi om et rum med f.eks. 1024 dimensioner, så hver bid får et langt koordinat i det rum, som kunne være noget i denne stil (1.3434,0.343,-0.166,...,0.687)

Ollama er et værktøj, der gør det muligt at køre nogle mindre sprogmodeller på din egen laptop uden et sindssygt grafikkort, og så skal man bare vælge en passende sprogmodel. Efter lidt research endte jeg med at vælge mxbai-embed-large, der er open source og er god til at lave embeddings på engelsksproget tekst.
Disse bidder gemmer vi så i en vektordatabase, som er en specialiseret database til at lave operationer på disse vektorer. Der er i dag rigtig mange muligheder at vælge imellem, og de store som PostgreSQL og Microsoft SQL Server er ved at komme med på vognen, men jeg har valgt QDrant, der udmærker sig ved at være ret lille og virkelig nem at komme i gang med. Og så er det den, der har lavet den farverige cluster-visualisering i toppen 😊
Semantisk søgning i bøger
For at søge i en vektordatabase sender man bare en tekst-embedding eller en koordinat afsted, og så får man de tekstbidder, der ligger semantisk tættest på.

Så man får noget, der semantisk betragtet er beslægtet, men ikke nødvendigvis har de samme ord i sig.
Det er jo vildt smart. Og egentlig nok i sig selv. Men vi skal dybere ind i skoven...
Giv kontekst med til LLM'en
Når man har søgt ned i sin vektordatabase og fået en række relevante bidder á ca 500 ord, kan man sende dem med til chatmodellen og sige "Givet de følgende kontekst-bidder, besvar spørgsmålet 'Hvad er meningen med sport?'" og så klistre bidderne i enden af spørgsmålet.
Og så får man måske et bedre svar der er mere groundet i det man vil vide, end hvis man bare havde fodret chatmodellen med det rå spørgsmål
Jeg bruger Meta's Llama 3.2, der også kan køre lokalt på min laptop. Det er ikke den skarpeste kniv i skuffen, men jeg bruger den primært til summarization her, så det går an. Alternativt kan jeg pege den på en AI model på Azure i Sverige, hvor jeg ved at der ikke bliver tracket.
Resultatet
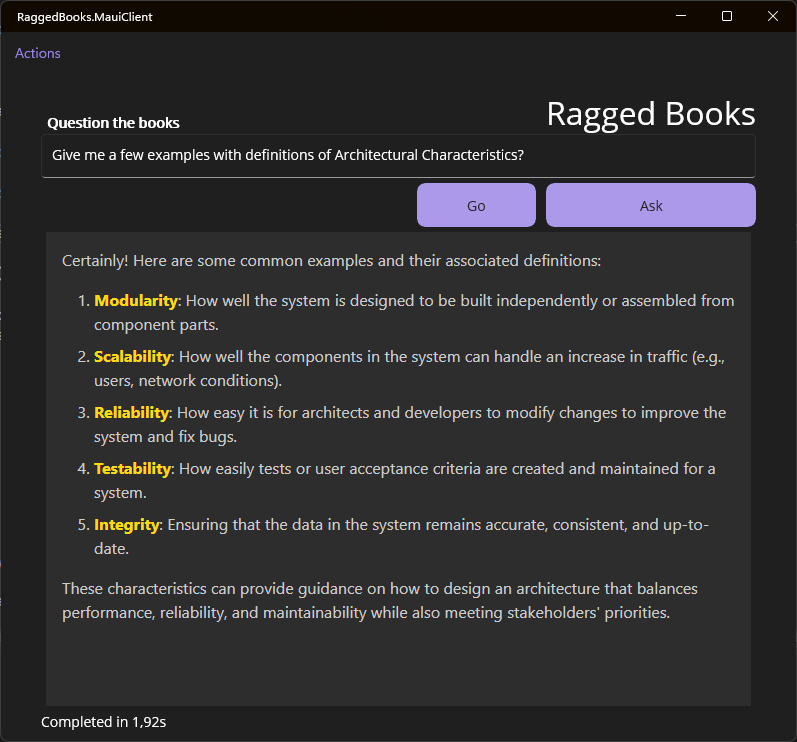
Killer-feature viste sig dog at være en utrolig effektiv søgning og dertil en funktion til direkte at åbne PDF'en i min browser på den side der matcher bedst. Og tastaturgenveje for speed!
Med lidt mere afpudsning og tuning kunne det blive et nyttigt værktøj for mig – f.eks. kan man forestille sig, at jeg indlæser en samling PDF'er, der beskriver, hvordan en integration til et økonomisystem hos KMD fungerer, og så kan jeg effektivt lave opslag og søgninger og på den måde sætte mig ind i et nyt domæne (her ville det også være nyttigt at fine-tune den underliggende system prompt, men det er en anden historie)
I forhold til hvordan jeg vil tage RAG-erfaringen med mig, er det klart for mig at selv for et trivielt lille værktøj som dette er mange tekniske beslutninger der skal tages - fx blev jeg nødt til at bygge en lille indholdsfortegnelseparser for at kunne annotere tekstbidderne med sidetal og kapitelnavne. Og måden at skære teksten op på er heller ikke perfekt endnu. Og så er der hele spørgsmålet om, hvordan man kunne indkapsle et lokalt værktøj som dette i noget, der kan distribueres til andre..
Det er også nyttigt at bygge sine ting, så man nemt kan udskifte de forskellige embeddingmodeller og chatmodeller, så man nemmere kan finde den rette balance mellem performance og kvalitet. Dog er kvaliteten af resultaterne temmelig svær at kvalificere på en beviselig måde.
På læringsfronten er der altså god gevinst :)
Og hvis du er kommet hertil i din læsning, er du blevet eksponeret for et af mine læringsmål: jeg skal afslutte mine teknologiske eksperimenter med en blogpost :)
Du kan finde koden til Ragged Books her: https://github.com/dalager/raggedbooks, og hvis du har spørgsmål eller kommentarer, kan du bare skrive.
Vil du selv prøve at køre det, skal du nok have en vis teknisk flair – og jeg tager gerne mod pull requests og feature requests, hvis du har lyst til at bidrage.