Software-dokumentation efter AI
")
- AI-agenter producerer rigtig meget tekst og er notorisk tøvende med at slette ting.
- Det gælder i høj grad også dokumentation.
- Konsekvensen er, at det bliver sværere at navigere, vedligeholde og finde den rigtige information.
- Et hjørne af en løsning kan være, at vi bruger klassiske teknikker og AI-sprogteknologiske værktøjer mod problemet.
- Med 🔥 skal 🔥 bekæmpes!
Dokumentation og store sprogmodeller
Når man taler om dokumentation af softwaresystemer, er det, der er god dokumentation for en stor sprogmodel, som regel også god dokumentation for mennesker.
For at en AI-model skal kunne hjælpe dig, har den brug for din unikke kontekst.
Den ved meget om verden, men den er lidt lost, når du spørger den om dit eget projekt, og du får noget i stil med "Hør, kammerat, spol lige lidt tilbage – jeg har lige brug for at vide lidt mere om din situation."
Kontekst er det, der bliver sendt med til ChatGPT, hver eneste gang du trykker på 'send', og i en chatsession er det alle spørgsmål og svar i jeres nuværende chattråd og dine generelle instruktioner om, hvordan du gerne vil behandles osv.
Når et AI-værktøj skal sige noget om dit softwareprojekt, skal det også have kontekst med. Og ofte er det dokumentation i form af tekstfiler i det helt skrabede Markdown-format og så naturligvis kildekode.
Jo bedre kortet er over vores softwaresystem, desto bedre burde AI-modellen være i stand til at svare på spørgsmål og løse programmeringsopgaver.
Problemet er så bare, at den hurtigt kommer til vejs ende ligesom landet i den utroligt korte Borges-novelle On Exactitude in Science, hvor et rige, så besat af kartografiens ædle kunst, kvæler riget selv under et kort i målestok 1:1.
Udfordringer med dokumentation i AI-boostede projekter
For de af os, der laver software, er dokumentation et tveægget sværd og har altid været det. Det er fantastisk, når det er let at læse, indeholder den information, man har brug for, og er opdateret. Ellers kan det være værre end ingenting.
Med AI-værktøjer kommer der mere kode, som udviklerne ikke selv har skrevet. Måske har de heller ikke læst koden, men ved cirka, hvad der foregår, og forhåbentlig er det testet rigtig grundigt.
Hvis man er samvittighedsfuld som AI-powered udvikler, sørger man også for, at der kommer mere dokumentation løbende — både så man selv og AI-modellerne har lettere ved at forstå, hvad der foregår.
Men: Hvis der er noget, vi alle har fundet ud af, så er det, at sprogmodeller har det, man kunne kalde et agency-problem: De føler meget stærkt for sproget – det er ligesom deres identitet. Så der kommer MEGET sprog og dokumentation ud.
Min oplevelse er, at der kommer en del skriveri, ikke kun fordi LLM'en vil det, men fordi man også selv ønsker det:
- Hvad er det her for noget, overordnet set?
- Hvad er det her subsystem for noget, sådan lidt high level?
- Hvad skal vi bruge det her modul i det her subsystem til?
- Hvad skal vi lave?
- Hvad er der blevet lavet?
- Hvordan skal vi lave ting?
- Hvor langt er vi nået i vores planer?
- Hvordan skal Claude/Copilot/Cline/Cursor opføre sig?
Alt sammen noget, der skal gemmes som Markdown-filer.
Betragtet som en statisk samling af information, ville det være udfordrende at arbejde med.
Men som dokumentation af et levende softwaresystem i kontinuerlig udvikling af AI-agenter med friske udviklertyper ved roret, er det et veritabelt mareridt:
Problemer for mennesker og maskiner
- Hvor skal vi dokumentere det her henne?
- Hvordan skal dokumentationen se ud?
- Hvilket abstraktionsniveau skal man bruge hvor?
- Hvordan kan min AI-agent huske at opdatere dokumentationen det rigtige sted?
- Hvordan sikrer jeg mig, at forældet dokumentation og andre irrelevante tekstdokumenter bliver slettet, og hvornår?
Strategi: brug endnu flere AI-værktøjer
Vi har allerede stor glæde af en del værktøjer, som de her AI-modeller kan benytte sig af: Automatiserede tests, formatering, typekontrol, scannere for kodeduplikation, kompleksitetsmetrikker, vulnerabilityscannere og alle mulige andre kontroller, der sikrer, at koden bevarer en form for stramhed. Og når et AI-værktøj har været i gang, bliver de her værktøjer kørt lige bagefter, og uanset hvor meget man så har indskærpet ordentlig opførsel og beskrevet hvordan koden forventes at skulle se ud, er der ALTID bid: noget er ikke helt, som ønsket. Konfronteret med problemet, kommer AI-modellen naturligvis med en masse snakken udenom og dårlige undskyldninger og bekræftelse af mine dybe indsigter i min afsløring af sjuskeriet. Og så må den op på hesten igen.
Så. Hvad nu, hvis man kan gøre det med dokumentation også?
Principper
Idéen er, at vi bruger gennemprøvede teknikker fra vores højteknologiske værktøjskasse:
Sprogteknologi
- Semantisk søgning med embeddings i en vektordatabase
- Clustering – gruppering baseret på embeddings
- AI-opsummering
- AI-labeling (zero- eller few-shot)
Moderne softwarepraksis
- Dokumentation som CI-fokus: validering, formatering og analyse af placering, duplikeret indhold, kompleksitet osv.
- Shift-left-princippet fra DevOps-bevægelsen, men udfoldet til dokumentation, så man tænker gardening ind i processerne fra start
- Udviklerværktøjer, der gør det svært for udviklere at fejle
Eksperimentet, en case og et konceptuelt værktøj
Projektet, jeg ville redde
Mit primære hyggeprojekt i øjeblikket er lavet i Python. Det indeholder ca. 40.000 linjer kode og er splittet ca. 50/50 op mellem kode og tests. Det består af en kerne, et API, en serverless RunPod-wrapper, en CI/CD-pipeline, en OpenTelemetry-stak, OIDC-auth, HuggingFace og Cloudflare R2 integrationer og desuden et håndrullet load-testing-system med noget rapportgenerering 😅.
Med andre ord: der er mange krydderier, selvom det er en ret enkel ret, og jeg har virkelig kæmpet med at holde dokumentationen i skak.
Væk fra sumpen
Jeg har bygget semantic-docs, et lille Python-værktøj, der vedligeholder en semantisk database lokalt (ChromaDB + SQLite) med alle Markdown-filer i mit projekt.
Det kan både bruges som et værktøj, der er tæt integreret i den løbende udviklingsproces, og som analyseværktøj for eksisterende dokumentation i projekter.
Integreret i udviklingsprocessen
-
Når en Markdown-fil bliver opdateret eller tilføjet, bliver den automatisk indekseret med embeddings, og GPT-5 bruges til at opsummere indholdet og gemme en opsummering og nogle labels eller tags i indekset også. For at vægte placeringen af den enkelte fil, bliver den samlede sti, fx
/docs/guidelines/testing/tdd_recipe.md, også taget med i den semantiske vægtning. -
Herefter bliver dokumentationsfilen valideret i forhold til den øvrige dokumentation:
- Er der et semantisk overlap mellem det her og anden dokumentation?
- Er filen placeret et fornuftigt sted i den samlede dokumentationsstruktur?
- Så bliver den kontrolleret af en "dokumentations-agent", der laver et dokumentationsreview af dokumentet og sørger for at fjerne tvivlsomt LLM-snask som "Du er awesome! Og projektet er nu perfekt og klar til produktion!"
Hvis noget er skidt her, får udvikleren og ikke mindst AI-værktøjet, som fx Claude Code, en fejl med beskrivelse af problemet. Det kan man så prøve at gøre noget ved.
Analyse af dokumentationskodebasen
En del af værktøjet er en clusteringfunktion, der, baseret på dokumentationen i vektordatabasen, prøver at finde semantiske grupperinger på tværs af filer.
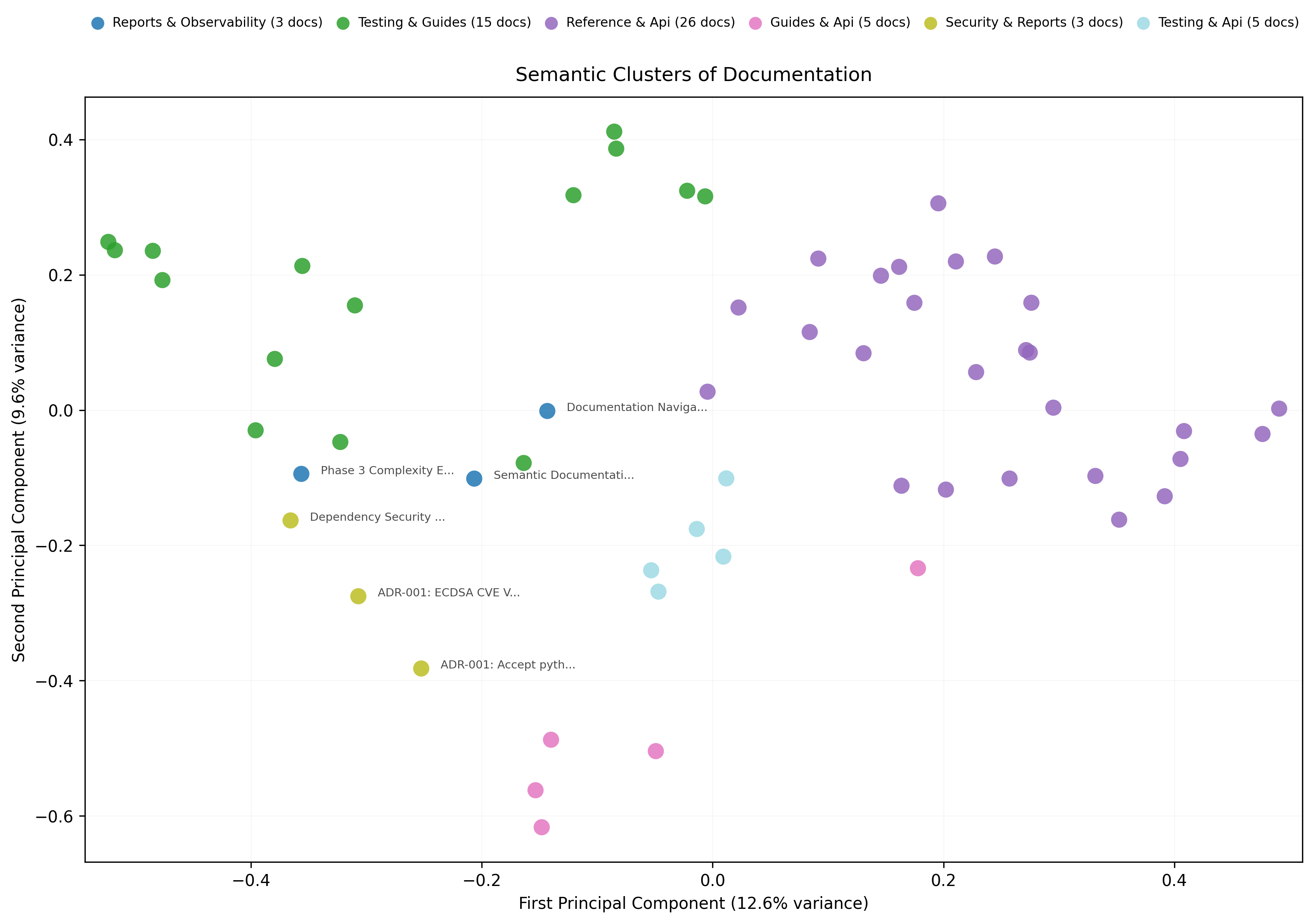
Kombinerer man disse mønstre med en analyse af, hvor der er en konflikt mellem fysisk placering og semantisk indhold – altså når nogen har puttet deres underbukser ned i sokkeskuffen – nærmer vi os noget, der rammer en del af vores behov.
Det er ikke helt let at forstå det billede, tænker jeg, men hvis man omsætter det til en konkret anvendelse, giver det mening, tror jeg.
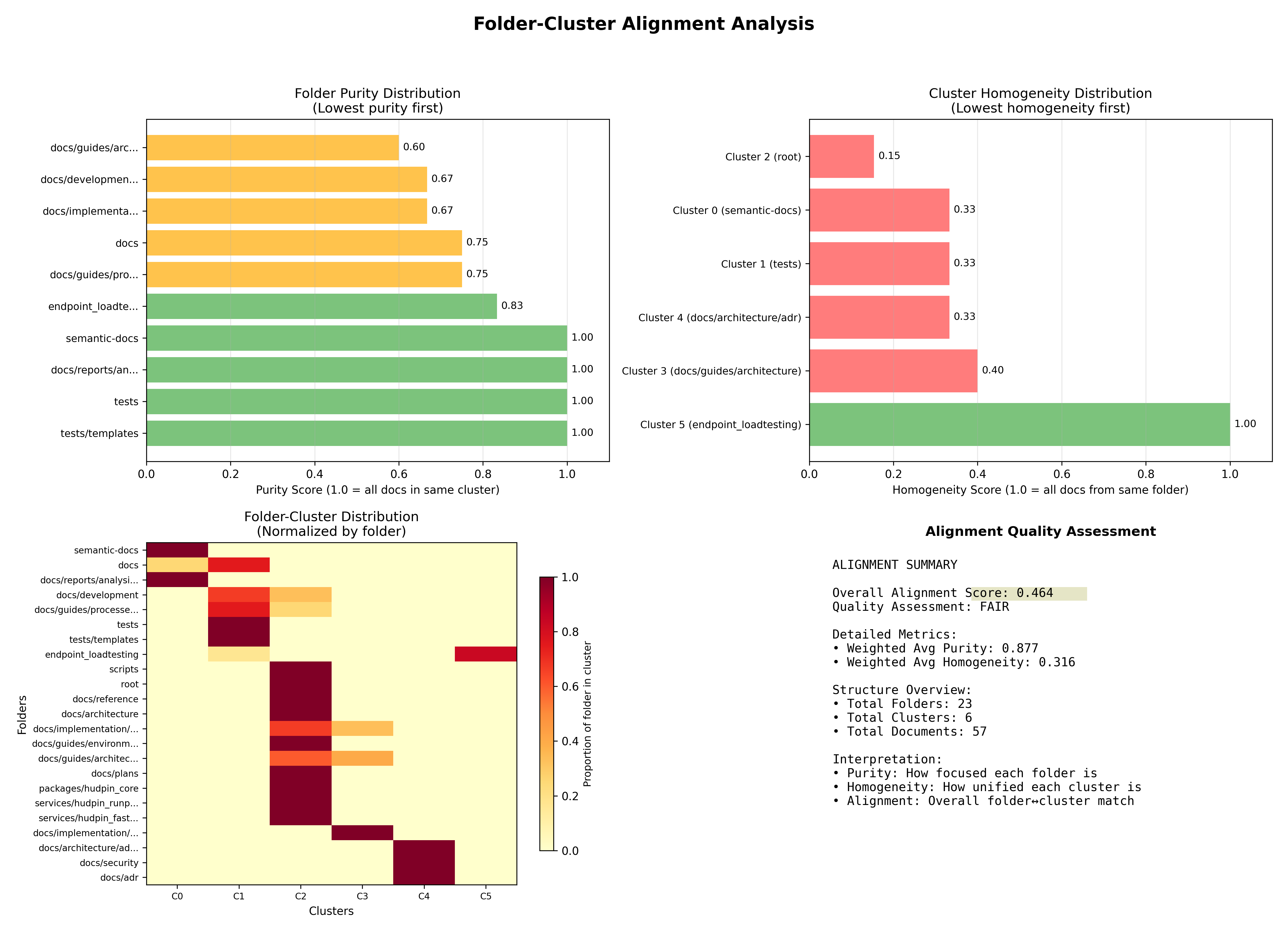
Her har jeg kørt værktøjet på hele projektet:
=================================================================
🏗️ FOLDER-CLUSTER STRUCTURE COMPARISON
=================================================================
📊 Overview:
Total Folders: 23
Total Clusters: 6
Total Documents: 57
Generated: 2025-08-26T22:06:04.326640
🎯 Overall Alignment:
🟠 Quality: FAIR (score: 0.464)
📁 Folder Purity: 0.877 (how focused folders are)
🗂️ Cluster Homogeneity: 0.316 (how unified clusters are)
📁 Folders Needing Attention (lowest purity first):
1. 🟡 docs/guides/architecture - purity: 0.60
(5 docs across 2 clusters)
2. 🟡 docs/development - purity: 0.67
(3 docs across 2 clusters)
3. 🟡 docs/implementation/features - purity: 0.67
(3 docs across 2 clusters)
4. 🟡 docs - purity: 0.75
(4 docs across 2 clusters)
5. 🟡 docs/guides/processes - purity: 0.75
(4 docs across 2 clusters)
🗂️ Clusters Needing Attention (lowest homogeneity first):
1. 🔴 Cluster 2 (root) - homogeneity: 0.15
(26 docs from 13 folders)
2. 🔴 Cluster 0 (semantic-docs) - homogeneity: 0.33
(3 docs from 3 folders)
3. 🔴 Cluster 1 (tests) - homogeneity: 0.33
(15 docs from 6 folders)
4. 🔴 Cluster 4 (docs/architecture/adr) - homogeneity: 0.33
(3 docs from 3 folders)
5. 🔴 Cluster 3 (docs/guides/architecture) - homogeneity: 0.40
(5 docs from 3 folders)Og på samme måde kan man tjekke enkeltstående dokumenter for, om de har en "god placering".
Konklusion
Jeg har brugt Claude Code som AI-agentplatform til forsøget, fordi Anthropic med deres MCP-protokol, Sub Agents, Hooks og Commands er længst fremme med tooling, synes jeg.
Tooling, der hjælper os til at skabe disse øer af non-determinisme, som er en nødvendighed, for at vores softwareløsninger ikke bare bliver big balls of mud, men mudrede sletter beboede af AI-spøgelser, som forældre advarer deres børn om at gå ud i.
Good
- Virkelig en god proces og måde at tænke tingene igennem på.
- Særligt semantic cluster vs filplacering giver en god indikation, man kan arbejde videre med.
Forbedringspunkter
- Det er ikke vildt hurtigt som hurtig feedback, når man udvikler.
- Det er lidt omstændigt at få Claude Hooks og Git pre-commit hooks til at give den gode ergonomi, når man arbejder.
- Bøvl:værdi-ratioen er på kanten. Men måske er det, fordi jeg har brugt så lang tid på at bygge det, at jeg synes det.
- Måske er det bare en liiidt for tænkt idé.
Takeaways
Er det noget, jeg vil arbejde videre med? Det er i hvert fald noget, jeg vil tænke videre over, og det vil helt sikkert påvirke den måde, jeg tænker dokumentation på i fremtiden, men om jeg vil gøre noget i denne stil, det er lidt uklart.
Det konkrete værktøj her ender muligvis ovre i bunken af prototyper, der har gjort mig klogere, men ikke verden bedre 🤷🐰
NB: Menneskelige læsere af dokumentation er nok en uddøende race. Og det er ikke helt uden ironi, men det er lidt en anden snak.
Jeg har pakket projektet lidt sammen: https://github.com/dalager/semantic-docs/ for de tekniske.
Referencer
ThoughtWorks Technology Podcast: Caring about documentation in the LLM era
Erfaren tech writer i studiet om emnet.
Latent Space Podcast: Long Live Context Engineering - with Jeff Huber of Chroma
Meget spændende episode om kontekstproblemer og løsninger i LLM'er.